XINC dissects Implicit Neural Representation (INR) models to understand how neurons represent images and videos and to reveal the inner workings of INRs.
Abstract
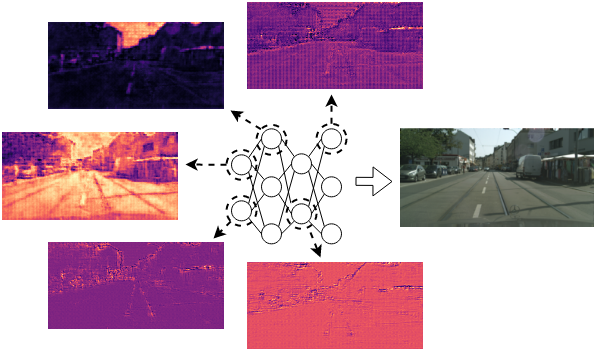
The many variations of Implicit Neural Representations (INRs), where a neural network is trained as a continuous representation of a signal, have tremendous practical utility for downstream tasks including novel view synthesis, video compression, and image super-resolution. Unfortunately, the inner workings of these networks are seriously understudied. Our work, eXplaining the Implicit Neural Canvas (XINC), is a unified framework for explaining properties of INRs by examining the strength of each neuron’s contribution to each output pixel. We call the aggregate of these contribution maps the Implicit Neural Canvas and we use this concept to demonstrate that the INRs we study learn to “see” the frames they represent in surprising ways. For example, INRs tend to have highly distributed representations. While lacking high-level object semantics, they have a significant bias for color and edges, and are almost entirely space-agnostic. We arrive at our conclusions by examining how objects are represented across time in video INRs, using clustering to visualize similar neurons across layers and architectures, and show that this is dominated by motion. These insights demonstrate the general usefulness of our analysis framework.
How does XINC work?
XINC dissects an INR to create contribution maps for each “neuron” (group of weights), which connect neurons to individual pixels in terms of their activations. Together, these contribution maps comprise the “implicit neural canvas” for a visual signal. XINC unveils surprising characteristics such as highly distributed representations, bias for low-level features like color and edges over space, lack of high-level object semantics and in video INRs, the dominance of motion in object representation.
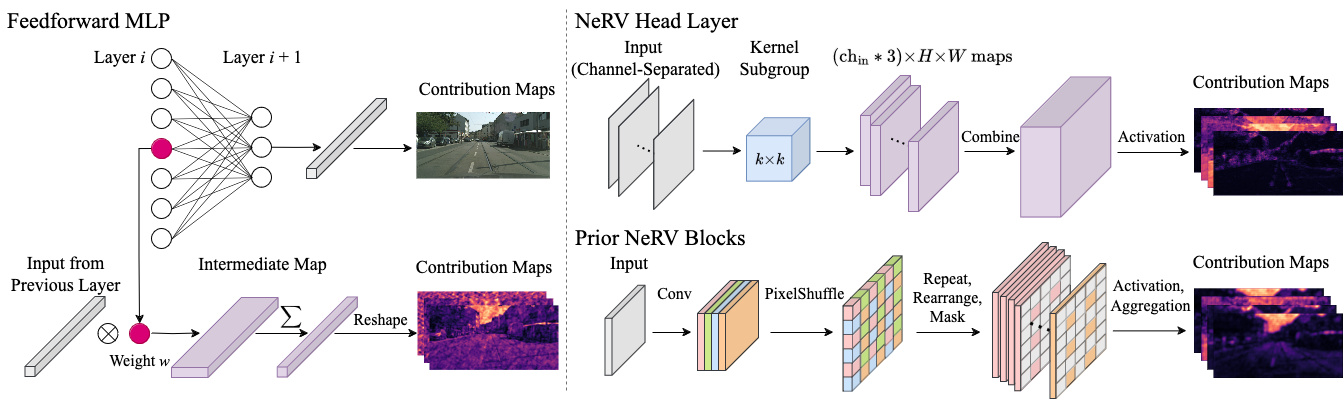
Left: We dissect MLP-based INRs such as FFN [1] by aggregating their activations (weights multiplied by previous layer outputs) for each pixel at each neuron. Right: We extend this core idea of pixel-to-neuron mapping for CNN-based INRs, NeRV [2] by computing intermediate feature maps that are not yet summed on the input dimension.
